
Sitemap Finder
The Definitive Guide to XML Sitemaps: A Strategic Blueprint for Search Engine Discovery and Indexation
Part I: The Foundational Blueprint: Understanding the “What” and “Why” of Sitemaps
Section 1.1: Defining the Sitemap Protocol
A sitemap is a file hosted on a website’s server that provides search engines with a structured list of the site’s URLs, along with valuable metadata about those URLs. Fundamentally, it functions as a direct communication channel and a “roadmap” for search engine crawlers, such as Googlebot, designed to help them discover and understand a site’s content more intelligently and efficiently. While there are several formats, the most common and versatile is the XML (Extensible Markup Language) sitemap.
The protocol was first introduced by Google in June 2005 to allow web developers to publish lists of links from their sites. Its significance was solidified in November 2006 when Google, Yahoo!, and Microsoft announced joint support for the protocol, establishing it as a universally recognized web standard. This collaborative backing, now managed through the non-profit sitemaps.org, underscores the protocol’s foundational importance in the field of technical search engine optimization (SEO).
It is critical to understand the core purpose of a sitemap: its primary function is to improve and guide the crawling process, not to act as a direct ranking factor or a guarantee of indexation. A sitemap tells search engines which pages and files a site owner believes are important. This distinction frames the sitemap not as a command, but as a strategic suggestion. The act of creating and submitting a sitemap is an exercise in content curation for search engines. It is a declaration of which content is deemed most valuable and, therefore, most worthy of a search engine’s finite crawl resources. A well-curated sitemap guides a crawler’s attention to the pages most likely to satisfy user queries and achieve business objectives. Conversely, a poorly managed sitemap that includes low-value, non-canonical, or broken URLs sends a negative signal about the site’s overall quality and technical diligence, potentially leading to inefficient use of crawl budget and hindering the discovery of valuable content.
Section 1.2: The Strategic Imperative: When and Why a Sitemap is Necessary
While not every website is strictly required to have a sitemap to be crawled and indexed, its implementation is a strategic imperative in several key scenarios. The presence of a sitemap can dramatically improve the efficiency and comprehensiveness of search engine crawling.
Key Scenarios Requiring a Sitemap:
- Large Websites: For sites with thousands or even millions of pages, such as large e-commerce stores or content publishers, ensuring every page is discoverable through internal linking alone is a monumental challenge. A sitemap provides a direct and reliable path for crawlers to find new or updated content that might otherwise be missed or discovered slowly.
- New Websites with Few External Links: Search engine crawlers primarily discover new content by following links from already known pages. A brand-new website with a minimal backlink profile is effectively an “island” on the web. A sitemap serves as the initial bridge, directly informing search engines of the site’s existence and structure, thereby kickstarting the discovery process.
- Complex or Poor Internal Linking: Websites may have “orphaned pages”—pages that have no internal links pointing to them—or a deep, convoluted architecture that makes some pages difficult to reach. A sitemap is essential for ensuring these isolated or deeply-nested pages are found by crawlers.
- Sites with Rich Media Content: For websites where images, videos, or news articles are a critical component of the user offering, specialized sitemap extensions are invaluable. These extensions allow webmasters to provide valuable context, such as video duration, image subject matter, or news publication dates, which helps this content get properly indexed and appear in specialized search results like Google Images, Video, and News.
Scenarios Where a Sitemap May Be Considered Redundant (with Caveats):
Google’s documentation suggests that some sites may not need a sitemap. These include:
- “Small” Websites: Sites with approximately 500 pages or fewer may not require a sitemap, but this is conditional upon the site being comprehensively linked internally.
- Sites with Strong Internal Linking: If all important pages on a site can be easily reached by following a logical trail of links starting from the homepage, crawlers can likely discover the site’s content effectively without a sitemap.
However, even when a sitemap is not strictly “necessary,” its value as an “insurance policy” and a diagnostic tool is immense. The effort to generate one using modern tools is minimal, yet the benefits are significant. Forgoing a sitemap, even on a small site, means willingly abandoning a primary diagnostic channel with search engines. While a site may be perfectly crawlable today, issues can arise unexpectedly from CMS updates, accidental noindex tag implementations, or structural changes. In such cases, the sitemap coverage report in Google Search Console is the first and most effective place to identify which pages are affected and why. The low cost of implementation versus the high value of this diagnostic capability makes having a sitemap a universally recommended best practice for websites of all sizes.
Section 1.3: Quantifying the SEO Benefits
The implementation of a well-structured sitemap delivers several tangible benefits that contribute directly to a site’s SEO performance and its relationship with search engines.
- Enhanced Crawl Efficiency: Sitemaps provide a clean, centralized list of all important URLs, allowing search engine bots to crawl a site more efficiently than by relying solely on following links from page to page. This is particularly critical for optimizing the “crawl budget”—the number of pages a search engine will crawl on a site within a certain timeframe—on large websites.
- Comprehensive Indexing: By providing a complete map, sitemaps help search engines find and index all important pages, especially those that might be buried deep within the site architecture, generated dynamically, or lack a sufficient number of internal links.
- Accelerated Discovery of Content: A dynamic sitemap, particularly when used in conjunction with an RSS/Atom feed, acts as a notification system. It promptly informs search engines about new or recently updated content, leading to faster indexing and ensuring that the freshest version of a page is reflected in search results.
- Improved Rich Media Indexing: For sites heavily reliant on visual or timely content, sitemaps with extensions for video, images, and news are crucial. They allow for the submission of specific metadata, such as video running time, image locations and captions, and news publication dates, which Google can use to create richer, more informative search listings.
- Critical Diagnostic Power: Submitting a sitemap to tools like Google Search Console unlocks invaluable reporting capabilities. The “Coverage” report, for instance, shows exactly which of the submitted URLs have been successfully indexed and, more importantly, which have encountered errors or have been excluded and why. This provides a clear, actionable feedback loop for diagnosing and resolving technical indexing issues.
Part II: The Architect’s Toolkit: Sitemap Formats, Structure, and Creation
Section 2.1: Anatomy of an XML Sitemap
The XML sitemap is the most versatile and widely supported format. Creating a valid XML sitemap requires adherence to specific structural and formatting rules defined by the protocol.
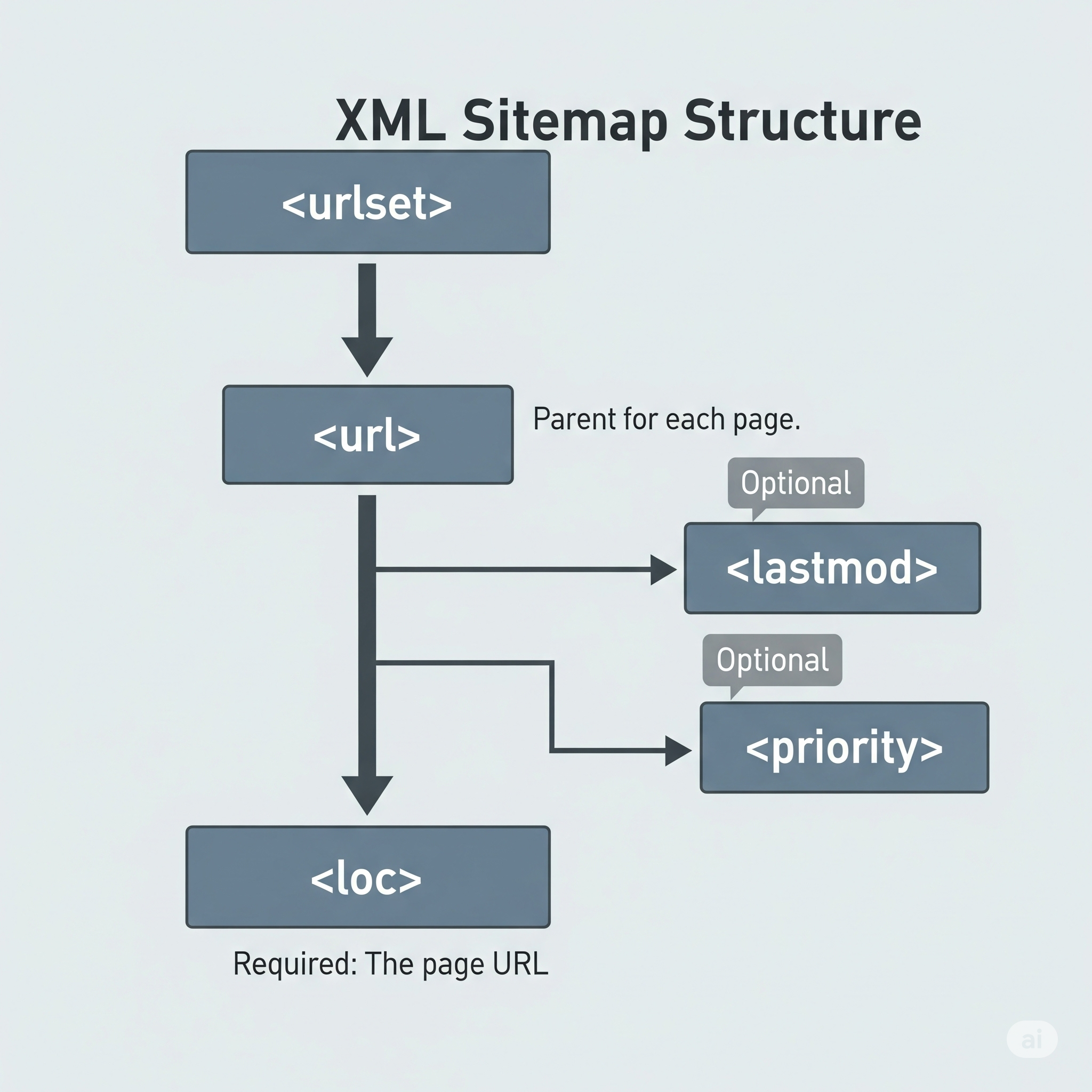
File Requirements:
- Encoding: The file must be UTF-8 encoded to ensure all characters can be correctly interpreted by search engines.
- Compression: Sitemap files can be compressed using Gzip (
.gz) to reduce file size and save server bandwidth. The uncompressed file must still adhere to the size limits.
Core Structure and Tags:
A valid XML sitemap is built upon a hierarchy of required tags:
- XML Declaration: Every sitemap must begin with an XML declaration that specifies the XML version and character encoding:
<?xml version="1.0" encoding="UTF-8"?>. <urlset>Tag: This is the required root element that encapsulates the entire list of URLs. It must also declare the sitemap protocol’s namespace:<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">.<url>Tag: This is a required parent tag for each individual URL entry. Every URL you wish to include must be wrapped in its own<url>tags.<loc>Tag: This is a required child tag inside each<url>element. It contains the full, absolute, and canonical URL of the page. The URL must begin with the protocol (e.g.,httporhttps), be less than 2,048 characters, and have special characters like ampersands (&) properly entity-escaped (as&).
Optional Tags and Their Modern Relevance:
While the protocol defines several optional tags, their relevance has evolved.
<lastmod>: This tag specifies the date the page’s content was last modified, using the W3C Datetime format (e.g.,YYYY-MM-DD). This is considered the most important optional tag. Google has stated that it uses this value as a signal for recrawling if it is consistently and verifiably accurate.<changefreq>: This tag was intended as a hint to crawlers about how frequently a page is likely to change (e.g.,daily,weekly,monthly). However, major search engines like Google now largely ignore this tag, relying on their own algorithms to determine crawl frequency. Including it is generally not necessary.<priority>: This tag was meant to indicate a URL’s importance relative to other URLs on the same site, on a scale from 0.0 to 1.0. Google has confirmed that it ignores this tag for ranking purposes. While some other search engines like Bing may still consider it as a minor hint, its overall value is minimal and it can be safely omitted from modern sitemaps.
The following table provides a quick-reference guide for the core XML sitemap tags.
| Tag Name | Required? | Description | Modern Best Practice & Notes |
|---|---|---|---|
<urlset> |
Yes | The root tag that encapsulates all URLs in the sitemap and declares the XML namespace. | Always use the standard namespace: http://www.sitemaps.org/schemas/sitemap/0.9. |
<url> |
Yes | A parent tag for each URL entry. Contains all information for a single URL. | Each URL you want to list must have its own <url> block. |
<loc> |
Yes | Contains the full, absolute URL of the page. | Must be the canonical version of the URL. Must be properly encoded and less than 2,048 characters. |
<lastmod> |
No | The date of the page’s last significant modification (W3C Datetime format). | Highly Recommended. Provide an accurate date. Do not update this value unless the page content has meaningfully changed. |
<changefreq> |
No | A hint about how often the page is likely to change (e.g., daily, never). |
Deprecated/Ignored. Google ignores this tag. It is safe to omit. |
<priority> |
No | The priority of a URL relative to other URLs on the same site (0.0 to 1.0). | Deprecated/Ignored. Google ignores this tag. It is safe to omit. |
Section 2.2: Exploring Alternative and Complementary Formats
While the XML format is the most robust, the sitemap protocol supports simpler formats and can be complemented by other feed types for a more effective crawl strategy.
- Plain Text (.txt) Sitemaps: This is the most basic format. It is a simple text file containing a list of URLs, with one URL per line. It must be UTF-8 encoded and adhere to the same 50,000 URL / 50MB size limits as XML sitemaps. The primary limitation of this format is its inability to include any additional metadata, such as the crucial
<lastmod>date. This makes it a viable, though less informative, option for very small, simple websites where providing metadata is not a priority. - RSS/Atom Feeds: RSS (Really Simple Syndication) and Atom feeds are standard formats for syndicating web content, commonly used for blogs and news sites. Search engines can accept these feeds as a type of sitemap. Their main purpose is to signal recent updates. Most Content Management Systems (CMS) generate these feeds automatically. They are typically small and are checked more frequently by search engines than large, comprehensive XML sitemaps.
For optimal crawling, the most effective strategy is to employ both a comprehensive XML sitemap and a dynamic RSS/Atom feed. These two formats serve distinct, complementary functions. The XML sitemap acts as the “comprehensive map,” providing search engines with a complete inventory of all important pages on the site, ensuring breadth of discovery. This is akin to a full census of the website. The RSS/Atom feed, on the other hand, functions as a “live bulletin” or a news flash, alerting search engines only to the most recent changes and new content, ensuring speed of discovery. Relying only on an XML sitemap might lead to delays in indexing new content, as a crawler may wait for its next scheduled crawl of the entire large file. Conversely, relying only on an RSS feed means that older, evergreen content that is no longer in the frequently updated feed may never be discovered. By implementing both, a webmaster ensures both comprehensive coverage and rapid discovery of new content.
Section 2.3: Methods of Sitemap Creation
Webmasters can choose from several methods to create a sitemap, ranging from simple manual creation to sophisticated automated systems.
- Manual Creation: This involves using a plain text or XML editor to write the sitemap file by hand. This method is only feasible for very small, static websites with a handful of pages. It is highly susceptible to human error (e.g., typos, syntax errors) and becomes unmanageable and difficult to keep updated as a site grows.
- Online Sitemap Generators: Numerous web-based tools can automatically generate a sitemap. The user provides their website’s URL, and the tool crawls the site to produce a downloadable sitemap file.
- Advantages: This method is fast, requires no coding knowledge, and is accessible for beginners.
- Disadvantages: These generators create a static snapshot of the site at a single point in time, which quickly becomes outdated as content is added or removed. They can only discover URLs that are accessible through links, meaning they will miss any orphaned pages. Furthermore, they often include every page they find by default, requiring the webmaster to manually edit the file to remove non-essential URLs.
- CMS Plugins (The Dynamic Solution): For websites built on a Content Management System like WordPress, plugins such as Yoast SEO or All in One SEO are the recommended method. These tools dynamically generate and manage sitemaps. They automatically update the sitemap whenever a post is published, a page is updated, or content is deleted. They often handle advanced tasks automatically, such as splitting sitemaps into smaller files when limits are reached, creating a sitemap index file, and even pinging search engines to notify them of updates. This automated approach is the most efficient and reliable for the vast majority of websites.
- Advanced Crawler-Based Generation: For maximum control and customization, a desktop crawler like the Screaming Frog SEO Spider is the tool of choice for technical SEO professionals. This software crawls a website and allows for highly granular configuration of the sitemap export. The user can define precisely which URLs to include or exclude based on a wide range of criteria, such as HTTP response codes,
noindexdirectives, canonical tags, or specific URL paths. This method provides unparalleled control, making it ideal for performing in-depth technical audits and for managing complex, custom-built websites that do not use a standard CMS.
Part III: Strategic Implementation and Management
Section 3.1: The Submission Process: Making Your Sitemap Discoverable
Creating a sitemap is only the first step; for it to be effective, search engines must be made aware of its existence and location. This is achieved through a multi-step submission and declaration process.
- Step 1: Proper Placement: The sitemap file should be uploaded to the root directory of the website (e.g.,
https://www.example.com/sitemap.xml). This is the recommended location because a sitemap’s scope is limited to affecting descendant directories. Placing it at the root ensures it can include URLs from across the entire site. - Step 2: Declaration in
robots.txt: The most fundamental way to inform all search engines about your sitemap is to declare its location in yourrobots.txtfile. This is done by adding a simple line of text with the absolute URL to your sitemap:Sitemap: https://www.example.com/sitemap.xml. If you use a sitemap index file, you should point to that file. This directive is independent of user-agent rules and serves as a primary discovery mechanism for crawlers. - Step 3: Submission to Google Search Console (GSC): Direct submission to GSC is crucial for monitoring and diagnostics.
- Log in to your Google Search Console account and select the correct website property.
- In the left-hand menu, navigate to the ‘Sitemaps’ report, which is located under the ‘Index’ section.
- In the ‘Add a new sitemap’ field, enter the relative URL of your sitemap (e.g.,
sitemap_index.xmlorsitemap.xml). - Click the ‘Submit’ button. GSC will then attempt to fetch and process the sitemap, providing a status report on its success and any errors found.
- Step 4: Submission to Bing Webmaster Tools: A similar process should be followed for Bing.
- Log in to your Bing Webmaster Tools account and select your site.
- Navigate to the ‘Sitemaps’ section (this may be under a ‘Configure My Site’ menu).
- Enter the full, absolute URL of your sitemap into the submission field.
- Click ‘Submit’. Bing will then process the file and report its status.
- Step 5 (Automated): Pinging: In the past, webmasters could manually “ping” search engines to request a crawl of an updated sitemap. Today, this process is largely automated by modern CMS plugins, which will ping search engines automatically after content is updated, ensuring timely discovery.
Section 3.2: Best Practices for a High-Performance Sitemap
A high-performance sitemap is not just a list of all pages; it is a clean, curated, and technically sound file that accurately reflects the site’s most important content. Adhering to best practices is essential for maximizing its effectiveness.
URL Inclusion Criteria (The “Clean List” Principle):
A sitemap should be a pristine list of your most valuable, index-worthy pages. Only include URLs that meet the following criteria:
- Canonical URLs: Always include the single, authoritative version of a page to avoid sending mixed signals about duplicate content.
- 200 (OK) Status Code URLs: The sitemap should only list live, working pages. Any URL that returns an error or redirect should be excluded.
- SEO-Relevant, Indexable Pages: The sitemap should only contain pages that you want to appear in search results and that are not blocked from indexing.
URL Exclusion Criteria (Crucial for Crawl Budget Optimization):
To maintain a clean sitemap and help search engines crawl your site efficiently, you must actively exclude the following types of URLs:
- Non-canonical versions of pages.
- Redirecting URLs (3xx status codes).
- Pages that return an error (4xx client errors like “Not Found” or 5xx server errors).
- Pages blocked from crawling via the
robots.txtfile. - Pages explicitly marked with a
noindexdirective. - Parameter-based URLs that create duplicate content (e.g., from tracking or filtering) and paginated pages beyond the first in a series.
- Utility pages that provide no unique value to a search user, such as login pages, shopping carts, internal search results, or thank-you pages.
Adherence to Technical Limits and Maintenance:
- Size and URL Limits: A single sitemap file must not contain more than 50,000 URLs and must not be larger than 50MB when uncompressed. If either of these limits is reached, the sitemap must be split into multiple smaller files, and a sitemap index file must be used to list them.
- Dynamic Generation and Accurate
<lastmod>: Static sitemaps are a liability because they quickly become outdated. A high-performance sitemap is generated dynamically by a CMS or script. Critically, the<lastmod>date must only be updated when a page’s content has undergone a meaningful change. Falsely updating this timestamp to the current date on every generation is a poor practice that can erode a search engine’s trust in the data provided.
The process of creating and maintaining a clean sitemap serves as a powerful forcing function for ensuring a site’s overall technical health. To properly exclude non-canonical, redirected, or broken pages, a webmaster must first identify them, which necessitates a comprehensive site crawl and audit. This process naturally uncovers underlying issues like duplicate content, broken internal links, and unnecessary redirect chains. Therefore, a pristine sitemap that validates correctly and contains only high-quality, indexable URLs is not merely a file; it is the tangible output of a well-maintained, technically sound website. The sitemap coverage report in GSC then becomes the continuous monitoring dashboard for that technical health.
Part IV: Advanced Sitemapping Strategies
Section 4.1: Managing Large and Enterprise-Level Websites
For websites with vast amounts of content, such as large e-commerce platforms, publishers, or sites with extensive user-generated content (UGC), a single sitemap is insufficient. Advanced strategies are required to manage complexity and ensure efficient crawling.
The Sitemap Index File:
The sitemap index is the essential tool for managing large websites. It is an XML file that does not contain URLs to individual pages; instead, it contains a list of URLs pointing to other sitemap files.
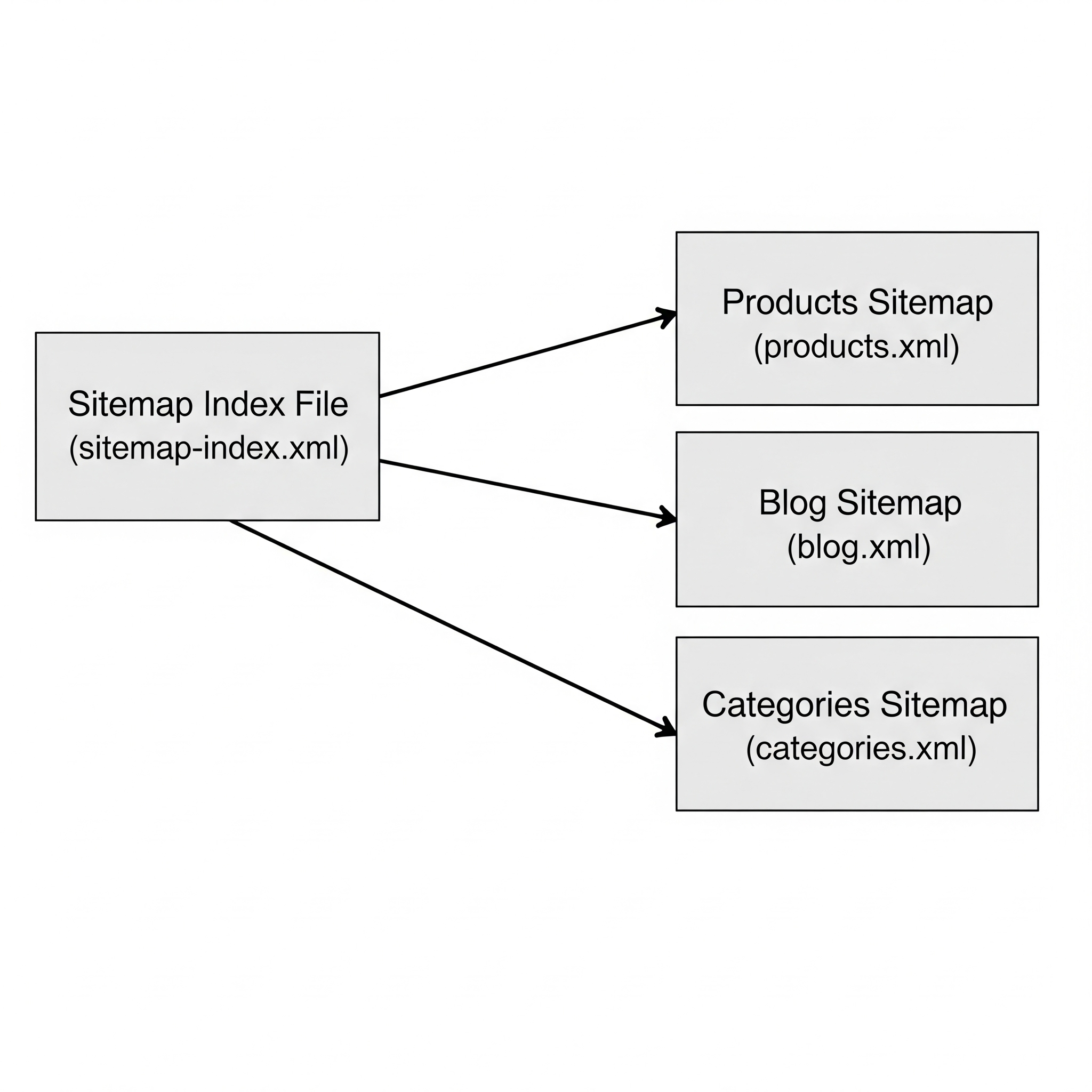
- Structure: It uses a similar but distinct XML format, with a
<sitemapindex>root tag and individual<sitemap>entries, each containing a<loc>tag for the location of a sitemap file. - Benefits: This approach allows a webmaster to submit a single index file to search consoles, which then discover all the constituent sitemaps. This dramatically simplifies management and, crucially, allows for more granular diagnostic tracking. If an indexing issue arises, GSC reports can help pinpoint whether the problem lies within the product sitemap, the blog sitemap, or another specific section of the site.
Strategic Segmentation:
For very large sites, it is a best practice to split sitemaps into logical, manageable segments. This segmentation provides more detailed data in GSC, helping to isolate indexing problems within specific areas of the website.
- By Content Type: This is a common and effective strategy. For example, an e-commerce site might have
products-sitemap.xml,categories-sitemap.xml, andblog-sitemap.xml. - By Date: For sites with a high volume of timely content, like news publishers or UGC platforms, segmenting by date (e.g.,
sitemap-2024-01.xml,sitemap-2024-02.xml) can be an effective way to manage the constant influx of new URLs.
Automation for High-Volume Sites:
For sites with a constant flow of new content, such as from user submissions, manual sitemap management is impossible. A custom, automated script or a robust CMS plugin is necessary. This system should be configured to dynamically update the relevant sitemap file (and its <lastmod> date) as soon as new content is published and approved. For massive sites with millions of pages, some evidence suggests that creating a larger number of smaller sitemap files can be more efficient for crawlers to process than having fewer files that are filled to the maximum 50,000 URL limit.
Section 4.2: Leveraging Sitemap Extensions for Rich Content
Beyond listing standard web pages, sitemaps can be extended with specific namespaces to provide detailed information about rich media content, enhancing its visibility in search results.
- Image Sitemaps: While search engines are adept at discovering images embedded within page content, an image sitemap is highly beneficial for sites where images are central to the business, such as stock photo websites, art portfolios, or e-commerce product galleries. An image sitemap allows you to explicitly list the locations of your important images, even if they are hosted on a Content Delivery Network (CDN), and provide additional metadata like captions. The protocol allows for up to 1,000 images to be listed per page. While modern best practices often lean towards using JSON-LD
ImageObjectschema markup for this purpose, image sitemaps remain a valid and fully supported method for promoting image discovery. - Video Sitemaps: A video sitemap is crucial for any site where video content is a key asset. It allows a webmaster to provide a wealth of rich metadata directly to search engines, including the video’s title, description, thumbnail URL, running duration, and even age-appropriateness ratings. This information can significantly enhance how the video is displayed in search results, increasing its visibility and click-through rate.
- Google News Sitemaps: This is a highly specialized sitemap format exclusively for publishers who have been approved for inclusion in Google News. It operates under strict guidelines: the sitemap must only include URLs for articles published within the last 48 hours, it must be updated constantly as new articles are published, and it is limited to a maximum of 1,000 URLs. If more URLs are needed, they must be split into multiple News sitemaps managed by a sitemap index.
- Hreflang Annotations in Sitemaps: For international websites targeting multiple languages or regions,
hreflangannotations are essential for signaling the correct page version to search engines. While these annotations can be placed in the<head>section of each HTML page, this can become cumbersome on large sites. A cleaner and more scalable solution is to include thehreflangannotations directly within the XML sitemap. This centralizes the management of international targeting signals into a single file, reducing the risk of errors and simplifying maintenance.
Part V: Diagnostics and Troubleshooting
Section 5.1: Decoding Google Search Console Sitemap Errors
Google Search Console (GSC) is the primary tool for diagnosing sitemap issues. When GSC encounters a problem processing a sitemap, it will report a specific error. Understanding these errors is the first step toward resolution.
- “Couldn’t fetch”: This is a fundamental accessibility error, meaning Googlebot was unable to retrieve the sitemap file.
- Common Causes: The sitemap URL provided is incorrect and results in a 404 “Not Found” error; the sitemap file is being blocked by a
Disallowrule in therobots.txtfile; the server was temporarily unavailable when Google tried to fetch it; or the site has an unresolved manual action against it. - Solution: First, verify that the sitemap URL is correct by visiting it in a browser. Second, check the
robots.txtfile for any rules that might be blocking the sitemap’s path. Third, use the URL Inspection Tool in GSC to perform a live test on the sitemap URL to confirm it is accessible to Googlebot. Finally, check the Manual Actions report to ensure the site is not penalized.
- Common Causes: The sitemap URL provided is incorrect and results in a 404 “Not Found” error; the sitemap file is being blocked by a
- “Sitemap had X errors” / “Invalid format”: This error means GSC was able to fetch the file but could not parse it correctly due to structural problems.
- Common Causes: The file contains invalid XML syntax (e.g., missing closing tags, incorrectly nested elements); the XML namespace is missing or incorrect; the file contains invalid characters or is not encoded in UTF-8; or the file exceeds the size (50MB) or URL count (50,000) limits.
- Solution: The most reliable first step is to use an online XML sitemap validator tool, which will often pinpoint the exact line and character causing the syntax error. Check for extra whitespace or characters before the initial
<?xmldeclaration. Ensure the file is saved with UTF-8 encoding. If the sitemap exceeds the limits, it must be split into smaller files and managed with a sitemap index.
- “URLs in sitemap are redirected”: Sitemaps should be a list of final destination URLs. Including URLs that redirect to other pages is inefficient and incorrect.
- Solution: The sitemap must be updated to replace any redirecting URLs with their final, canonical, 200-status destination URLs.
The following table summarizes common GSC errors and their solutions for quick diagnosis.
| GSC Error Message | Common Cause(s) | Step-by-Step Solution |
|---|---|---|
| Couldn’t fetch | Server unavailable; 404 error (wrong URL); Blocked by robots.txt; Manual action. |
1. Verify the sitemap URL is correct and live. 2. Check robots.txt for blocking rules. 3. Use the URL Inspection Tool to test fetchability. |
| Sitemap is HTML | The sitemap URL points to a standard HTML page instead of an XML file. A common issue with some caching plugins. | 1. Ensure the URL points directly to the .xml file. 2. Check caching plugin settings that might be serving a cached HTML version to bots. |
| URL blocked by robots.txt | A Disallow rule in robots.txt is preventing Google from accessing the sitemap file. |
1. Identify the blocking rule in your robots.txt file. 2. Modify or remove the rule to allow access to the sitemap URL. |
| Missing XML tag | The sitemap is missing a required tag (e.g., <url>, <loc>) or is completely empty. |
1. Use an XML validator to identify the missing tag. 2. Ensure the sitemap contains at least one valid URL entry. |
| Invalid URL | A URL listed in the sitemap is not a valid, absolute URL (e.g., it’s a relative URL, or contains syntax errors). | 1. Review the sitemap file for the invalid URL. 2. Correct the URL to be a full, absolute path (e.g., https://www.example.com/page). |
| URLs in sitemap are redirected | The sitemap contains URLs that redirect (301/302) to other pages. | 1. Crawl the URLs from your sitemap to identify which ones are redirecting. 2. Update the sitemap to replace the redirecting URLs with their final destination URLs. |
Section 5.2: A Troubleshooting Framework
When faced with a sitemap issue, a systematic approach can quickly identify and resolve the problem.
- Step 1: Locate the Sitemap: Before you can validate or inspect a sitemap, you need to find it. Websites don’t always use the standard
sitemap.xmllocation. If you’re auditing a site and don’t know the sitemap’s URL, you can check therobots.txtfile or use our free Sitemap Finder Tool to locate it instantly. - Step 2: Validate: The first and most important step is to run the sitemap URL through a trusted online XML validator tool. This will immediately catch the majority of syntax errors, such as unclosed tags, invalid characters, or incorrect nesting, which are the most common causes of parsing failures.
- Step 3: Inspect: Use the Google URL Inspection Tool on the sitemap URL itself. This will confirm whether Google can successfully fetch the file from your server. A “Successful” fetch rules out server-level or
robots.txtblocking issues. - Step 4: Check
robots.txt: Manually review yourrobots.txtfile to ensure there are noDisallowrules that inadvertently block access to the sitemap file or the directories containing the content listed within it. - Step 5: Review Caching Mechanisms: Aggressive server-side or plugin-based caching can sometimes serve an old, outdated version of the sitemap file, preventing updates from being seen by search engines. Purging the site’s cache after making significant content changes is a common and effective troubleshooting step.
- Step 6: Isolate Plugin Conflicts (for CMS users): On platforms like WordPress, a poorly coded plugin can sometimes interfere with sitemap generation, for example, by injecting whitespace or code into the XML file, which invalidates it. A standard diagnostic procedure is to temporarily disable other plugins one by one to see if the sitemap issue resolves, thereby identifying the conflicting plugin.
Part VI: The Sitemap Ecosystem: Context and Coexistence
Section 6.1: XML Sitemap vs. HTML Sitemap
While their names are similar, XML and HTML sitemaps serve fundamentally different purposes and audiences. A comprehensive web strategy often involves using both.
- Audience: The primary distinction lies in the intended audience. XML sitemaps are written in a machine-readable format and are created exclusively for search engine bots. HTML sitemaps are standard web pages designed to be read and used by human visitors.
- Purpose: The purpose of an XML sitemap is to provide a comprehensive list of URLs with technical metadata to improve the efficiency and completeness of a search engine’s crawl. The purpose of an HTML sitemap is to provide a user-friendly, hierarchical overview of the website’s main sections, improving site navigation and user experience.
- SEO Value: XML sitemaps have a direct technical SEO value by directly influencing how search engines discover and crawl content. HTML sitemaps offer indirect SEO value; by improving user experience, they can positively affect engagement signals like time on site and reduced bounce rates. Furthermore, an HTML sitemap provides an additional set of organized internal links that crawlers can follow, reinforcing the site’s structure. Because they serve these distinct but complementary roles, it is a best practice for many sites to implement both.
Section 6.2: XML Sitemap vs. Robots.txt
The XML sitemap and the robots.txt file are the two foundational pillars of crawl management. They have opposite but perfectly complementary functions, working in tandem to guide search engine behavior on a website.
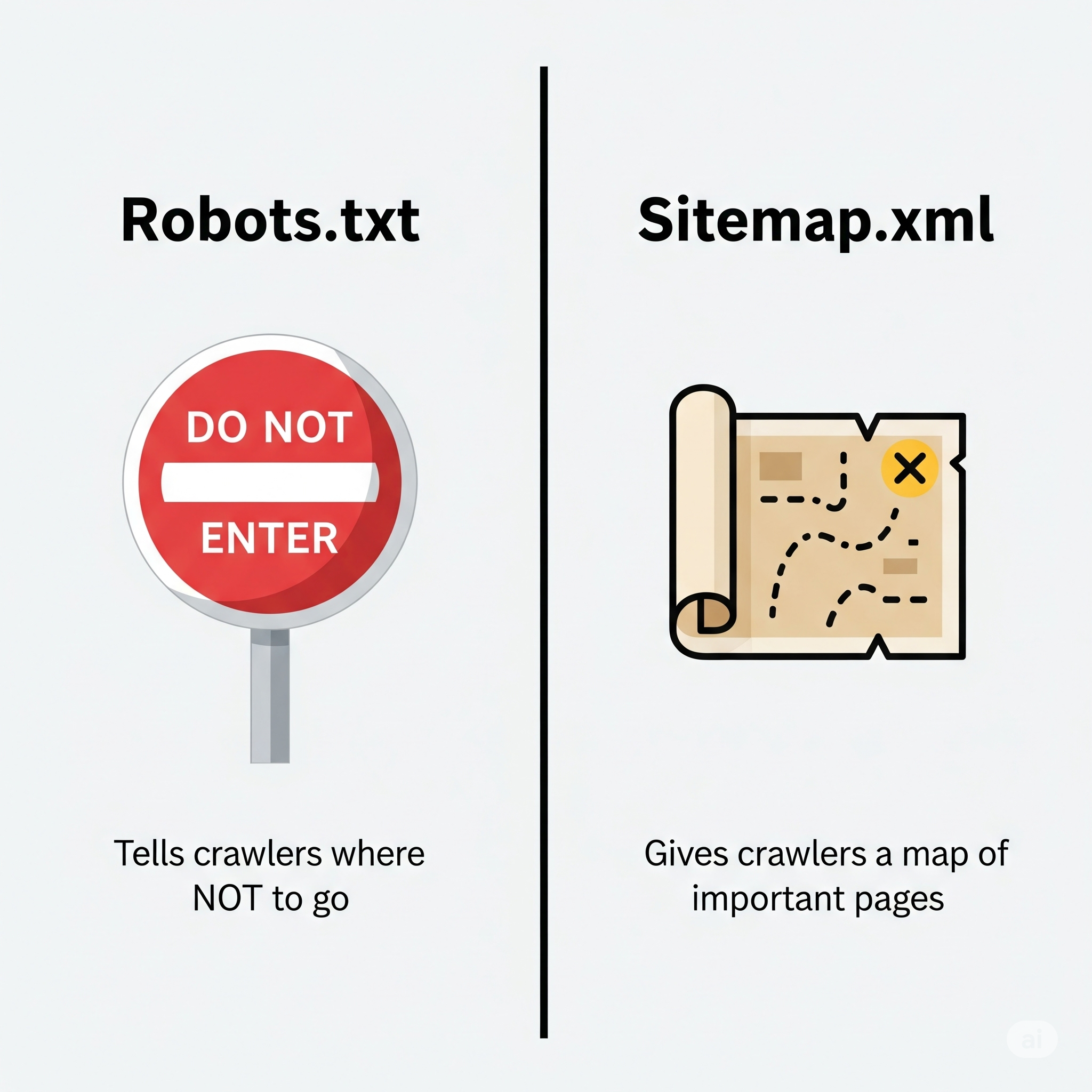
A Tale of Two Directives: Inclusion vs. Exclusion.
Robots.txt(The Gatekeeper): This file’s primary purpose is exclusion. It usesDisallowdirectives to tell search engine bots which parts of the site they are not allowed to access or crawl. This is used to prevent crawlers from accessing low-value areas like admin panels, internal search results, or duplicate content, thereby preserving the site’s crawl budget for more important pages.- XML Sitemap (The Map): This file’s primary purpose is inclusion. It provides a curated list of all the pages you want search engines to discover and crawl, effectively highlighting what you consider to be your most important content.
Synergy in Action: These two files work in harmony to create an efficient crawl path. A webmaster first uses the robots.txt file to close the doors to irrelevant or problematic sections of the site. Then, within that same robots.txt file, they use the Sitemap: directive to hand the crawler a map that points directly to all the important, high-value destinations. This combined approach ensures that search engine resources are spent efficiently, focusing only on the content that is meant to be discovered and indexed.
Conclusion: The Sitemap as a Strategic Asset
The XML sitemap has evolved far beyond its initial conception as a simple list of URLs. It is a dynamic and strategic asset that forms a cornerstone of modern technical SEO. A sitemap is a direct line of communication with search engines, a declaration of a site’s most valuable content, and an indispensable tool for diagnosing and resolving indexing issues.
The perception of the sitemap must shift from that of a static, set-and-forget file to a living document that reflects the health and priorities of a website. A high-performance sitemap—one that is dynamically generated, technically valid, and thoughtfully curated to include only canonical, indexable URLs—is a hallmark of a well-maintained and technically proficient website. The process of achieving this clean state forces a level of technical diligence that benefits the entire site, uncovering and resolving issues that might otherwise go unnoticed.
Ultimately, a properly implemented sitemap strategy fosters a positive and efficient relationship with search engines. By making their job of discovering and understanding content easier, webmasters can improve the speed and comprehensiveness of their site’s indexation, enhance the visibility of rich media, and gain critical feedback through search console reporting. In the complex ecosystem of the modern web, the XML sitemap is not merely a technical requirement; it is a strategic instrument for maximizing search visibility.
Need to find a website’s sitemap?
Whether you’re conducting an SEO audit or analyzing a competitor, the first step is finding their sitemap. Use our free tool to instantly locate the sitemap for any domain.
Use the Free Sitemap Finder